|
Architectures using multiple processors within the same computer are referred to as Symmetric Multiprocessing systems. Multiprocessor architectures improve overall performance by allowing threads to execute in parallel. As Law and Yagel's traversal scheme [22] was originally developed for parallelization, it is straight-forward to apply it to SMP architectures. Since the blocks contained in each block list are independent, they can be distributed among the available physical CPUs.
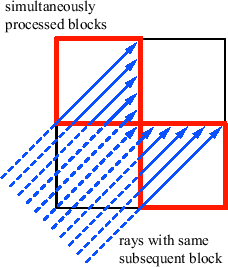
A possible problem occurs when rays from two simultaneously processed blocks have the same subsequent block, as shown in Figure 3.12. As blocks processed by different CPUs can contain rays which have the same subsequent block, race conditions occur when both CPUs simultanously try to assign rays to the ray list of one block. One way of handling these cases would be to use synchronization primitives such as mutexes or critical sections to ensure that only one thread can assign rays at a time. However, the required overhead can decrease the performance drastically. Therefore, to avoid race conditions when two threads try to add rays to the ray list of a block, each block has a ray list for every physical CPU. When a block is being processed, the rays of all these lists are cast. When a ray leaves the block, it is added to the new block's ray list corresponding to the CPU currently processing the ray.
|
|
The basic algorithm processes the pre-generated block lists in passes. The ProcessVolume procedure (see Algorithm 7) is executed by the main thread and distributes the blocks of each pass among the available processors. It starts the execution of ProcessBlocks (see Algorithm 8) in a thread for each of the processors. ProcessBlocks traverses the list of blocks assigned to a processor and processes the rays of each block. ProcessRay performs resampling, gradient estimation, shading, and compositing for a ray, until it leaves the current block or is terminated for another reason (e.g., early ray termination). It returns true if the ray enters another block and false if no further processing of the ray is necessary. ComputeBlock returns the new block of a ray when it has left the current block. In the listed procedures,
![]() is the number of physical CPUs in the system.
is the number of physical CPUs in the system.

![\begin{algorithm}
% latex2html id marker 1071\footnotesize
\caption{ProcessB...
...st[i]$,$r$)
\ENDIF
\ENDFOR
\ENDFOR
\ENDFOR
\end{algorithmic}\end{algorithm}](img195.png)