The goal of raycasting is the (approximate) calculation of the volume rendering integral for every viewing ray originating at the image plane and passing through the volume. This evaluates to advancing rays through the volume with regular increments ![]() (i.e. the object sample distance) and performing the following steps at each location:
(i.e. the object sample distance) and performing the following steps at each location:
 |
|
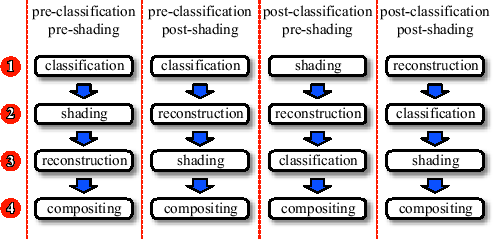
There are several possibilities in which order these steps can be performed (see Figure 3.1): Both classification and shading can occur before reconstruction (pre-classification, pre-shading) or after reconstruction (post-classification, post-shading).
Pre-classification assigns a color and an opacity to the samples before applying a reconstruction filter. Post-classification, on the other hand, applies to reconstruction filter to the original sample values and then classifies the reconstructed function values. Pre- and post-classification will produce different results, whenever the reconstruction does not commute with the transfer functions. As the reconstruction is usually non-linear, it will only commute with the transfer functions if the transfer functions are constant or identity.
Pre-shading means that the illumination model is evaluated at the grid points only. Post-shading reconstructs the gradient (and/or other parameters required for evaluating the illumination model) at every resample location and then evaluates the illumination model. Again, pre-shading and post-shading are only equivalent if the lighting model is constant or an identity function of its parameters.
The loss in image quality caused by pre-classification and pre-shading has been previously discussed [5]. We have performed a comparison of all four variants using floating-point precision calculations throughout the pipeline. As shown in Figure 3.2, pre-classification causes the most severe artifacts. The differences between pre-shading and post-shading are more subtle, but still clearly visible. Our approach therefore uses both, post-classification and post-shading.
The following sections will discuss reconstruction, classification, shading, and compositing in detail.
![\includegraphics[width=6.5cm]{algorithm/images/preclassification_preshading.eps}](img48.png)
![\includegraphics[width=6.5cm]{algorithm/images/preclassification_postshading.eps}](img49.png)
![\includegraphics[width=6.5cm]{algorithm/images/postclassification_preshading.eps}](img50.png)
![\includegraphics[width=6.5cm]{algorithm/images/postclassification_postshading.eps}](img51.png)